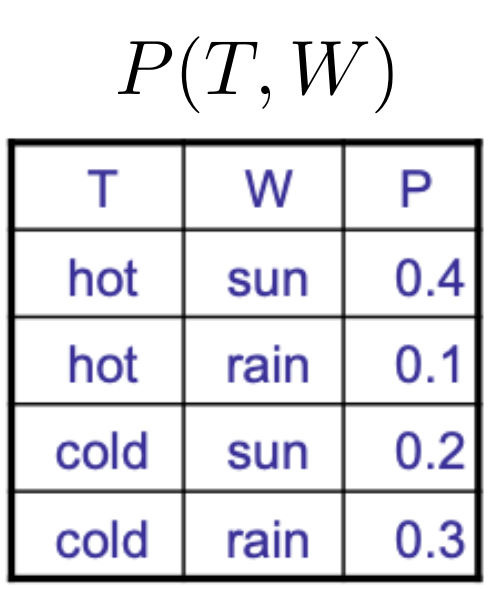
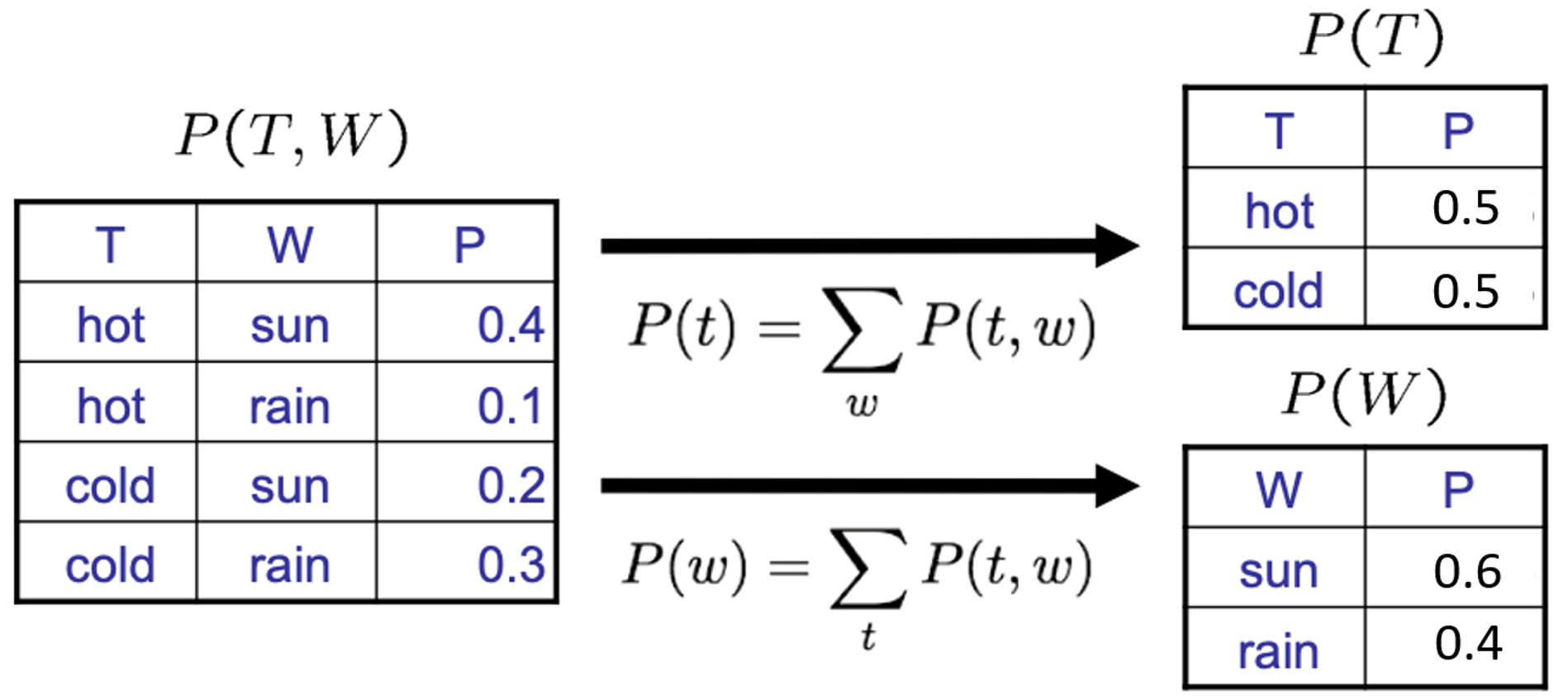
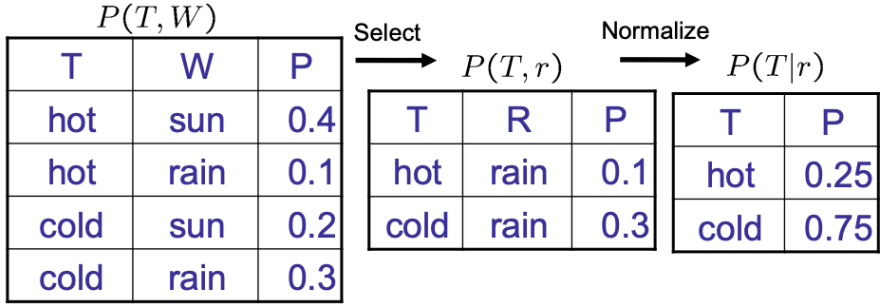
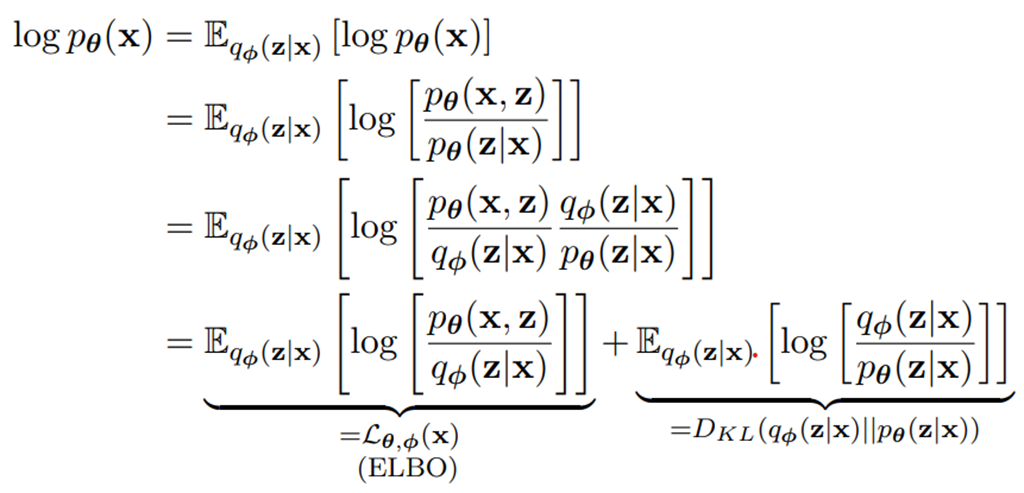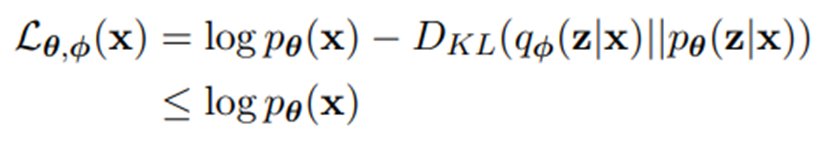본문에서는 Pytorch 사용을 위한 전반적인 내용들과 코드에 대한 설명을 다룬다.
특히, Tensor의 정의와 Tensor를 대상으로 하는 함수들에 대해 다룸으로써 딥러닝 및 머신러닝 구현에 필수적인 내용을 알아본다.
본문에서 작성한 명령어 중 tensor.함수이름() 의 tensor 는 정의된 Tensor 를 뜻하며, 일관성을 위해 통일하였다.
1.1 - Tensor 정의
딥러닝에서 Tensor는 간단하게 행렬(matrix)의 집합이라고 정의할 수 있다. 특히, 주로 3 차원 이상의 배열의 집합을 Tensor라고 한다.
- Vector : 1d-tensor 라고도 표현한다.
- Matrix : 2d-tensor 라고도 표현한다.
Tensor의 정의는 Pytorch에서 torch.tensor() 함수를 통해 이루어진다.
이 함수를 통해 numpy의 array를 tensor로 변환할 수도 있다.
(코드)
import torch
import numpy
a = torch.tensor([1,2,3])
b = numpy.array([1,2,3])
c = torch.tensor(b)
1.2 - Tensor 모양, 차원
-
tensor.shape: Tensor의 모양을 반환한다.
(코드)
a = torch.tensor([[1,2,3], [3,4,5]]) print(a.shape)(결과)
torch.Size([2, 3]) -
tensor.ndim: Tensor의 차원 수를 반환한다.예를 들어, 23 행렬 같은 경우 2를, 23*4 tensor같은 경우 3을 반환한다.
(코드)
a = torch.tensor([[1,2,3], [3,4,5]]) print(a.ndim)(결과)
2 -
tensor.numel(): Tensor의 성분 개수를 반환한다.Tensor 안의 모든 성분의 개수를 반환하는 함수이다. 이 함수는 특히 Network의 parameter 수를 파악할 때 유용하게 사용된다.
(코드)
a = torch.tensor([[1,2,3], [3,4,5]]) print(a.numel())(결과)
6
1.3 - Indexing & Slicing
Indexing & slicing
-
Indexing & Slicing : Pytorch에서 Tensor의 indexing은 python에서 list의 indexing과 유사하다. 그러나 일부 차이점이 있으며, 이는 대규모 data를 다룰 때 편리한 기능을 제공한다.
tensor[시작 : 마지막 전 : 간격]명령어를 통해 indexing 및 slicing을 진행한다. 이는 list의 그것과 동일하다. 그러나 아래 명령어들은 list와 차별화 된다.tensor[1,3]:tensor[1][3]과 같은 명령어이다.tensor[ : , 3]: 모든 행의 3번째 열
(코드)
a = torch.tensor([ [1,2,3], [4,5,6], [7,8,9] ]) print(a[1,2]) print(a[:,2])(결과)
tensor(6) tensor([3, 6, 9])
Boolean Indexing
-
Boolean Indexing : Pytorch는 tensor에 대해 boolean 연산을 지원한다.
즉, boolean 연산을 통해 원하는 조건을 만족하는 요소들의 index 혹은 해당 요소들을 직접 얻을 수 있다.
아래는 가장 기본이 되는 조건문을 통한 boolean indexing이다. 조건문을 만족하는 요소 혹은 boolean 값을 얻을 수 있다.
-
tensor == 10: tensor의 각 요소에 대해 10과 같으면 True, 다르면 False 반환
(코드)
a = torch.tensor([1,2,3,4,5,6]) print(a==3)(결과)
tensor([False, False, True, False, False, False]) -
tensor[tensor==10]]: tensor의 요소 중 10인 요소들만 return한다.
(코드)
a = torch.tensor([1,2,3,4,5,6]) print(a[a==3])(결과)
tensor([3])
역으로, boolean 값을 통해
True인 자리의 요소만 얻을 수 있다.-
같은 shape의 boolean tensor을 이용한 indexing
(코드)
a = torch.tensor([1,2,3,4,5,6]) b = torch.tensor([True, False, False, True, False, False]) print(a[b])(결과)
tensor([1, 4]) -
[행], [열]로 indexing : 아래 코드에서 첫 째 list는 행의 위치를, 두 번째 list는 열의 위치를 나타낸다. 따라서 1행과 4행의 두 번째 열에 해당되는 요소를 return 한다.
(코드)
a = torch.tensor([ [1,2],[3,4],[5,6],[7,8] ]) print(a[[True, False, False, True], [False, True]])(결과)
tensor([2, 8])
-
Tensor로 Indexing
- Tensor로 Indexing : 파이썬의 list indexing에서는
[ ]안에 정수 혹은2:5와 같은 slices만 사용할 수 있다. 그러나 Pytorch의 Tensor에서는[ ]안에 tensor type 또한 사용 가능하며, 이를 통해 다양한 indexing이 가능하다.-
tensor[torch.tensor(1)]:tensor[1]과 동일하다.
(코드)
a = torch.tensor([1,2,3,4,5]) b = a[torch.tensor(1)] print(b)(결과)
tensor(2) -
tensor[torch.tensor([3,4,5,6]):tensor[3:7]과 동일하다.
(코드)
a = torch.tensor([1,2,3,4,5,6,7,8]) b = a[torch.tensor([3,4,5,6]) print(b)(결과)
tensor([4,5,6,7]) -
tensor[torch.tensor([[1,1,1], [3,3,3]])]:tensor[1],tensor[3]으로 2*3 행렬 생성한다.
(코드)
a = torch.tensor([1,2,3,4,5,6,7,8]) b = a[torch.tensor([[1,1,1], [3,3,3]]) print(b)(결과)
tensor([[2, 2, 2], [4, 4, 4]])
-
1.4 - Pytorch의 여러 함수
Pytorch에는 Tensor을 위한 여러 함수가 있다. 이 함수들은 Tensor를 이용한 여러 기능을 제공하고, 머신러닝 및 딥러닝 구현을 편리하게 한다.
각종 수학 연산
-
각종 수학 연산 : tensor를 입력하면 각 요소에 해당 함수를 적용하여 tensor를 return한다.
(코드)
print(torch.abs(A)) #절대값 print(torch.sqrt(torch.abs(A))) print(torch.exp(A)) print(torch.log(torch.abs(A))) print(torch.log(torch.exp(torch.tensor(1)))) #torch 함수 내에는 torch.tensor가 input print(torch.log10(torch.tensor(10))) #1 print(torch.log2(torch.tensor(2))) #1 print(torch.round(A)) #반올림 print(torch.round(A, decimals=2)) #소수점 둘째자리 print(torch.floor(A)) #내림 print(torch.ceil(A)) #올림 print(torch.sin(torch.tensor(torch.pi/6))) print(torch.cos(torch.tensor(torch.pi/3))) print(torch.tan(torch.tensor(torch.pi/4))) print(torch.tanh(torch.tensor(-10)))
Tensor 생성함수
torch.randn(): Normal Distribution에서 random sampling한 tensor를 주어진 모양의 요소만큼 return한다.- 이때, +n 을 통해 평균을 +n 할 수 있다.
- *n 을 통해 분산을 *n^2 할 수 있다.
(코드)
a1 = torch.randn(3,3) a2 = torch.randn(3,3)+10 #평균을 10으로 바꿈 a3 = torch.randn(3,3)*10 #분산을 100으로 바꿈(결과)
tensor([[-0.9033, 0.0684, -1.4416], [ 0.4585, -0.6715, -0.5306], [-0.7244, 0.6607, 0.7440]]) tensor([[10.0661, 10.6357, 9.0546], [ 9.7324, 11.3257, 11.1073], [10.3477, 9.5452, 9.4528]]) tensor([[ -0.8509, 3.0854, -15.2621], [ -0.7088, 3.7370, -10.7181], [ 0.4594, -13.4798, -14.3943]])-
torch.randint(a, b, size=(c,d)): a부터 b 미만의 임의의 정수로 이루어진 c*d 모양의 tensor 생성한다.
(코드)
a = torch.tensor(1,8, size=(3,4)) print(a)(결과)
tensor([[3, 3, 4, 1], [2, 1, 5, 4], [6, 3, 1, 6]])
max, min, argmax 함수
-
torch.max(tensor, dim = n, keepdims=True): tensor를 dim=n으로 접는다. 예를 들어, dim=0이면 열 중 max 값을 구해 결과적으로 행으로 접게 된다. 이 때, keepdims를 True로 설정하면 원본의 차원을 그대로 유지한다.(
torch.min()도 동일)
(코드)
a = torch.randn(3,4) print(a) print(torch.max(a, dim=0) print(torch.min(a, dim=1) print(torch.max(a, dim=0, keepdims=True))(결과)
tensor([[ 0.2120, 1.0677, 0.8159, -0.0084], [ 1.7350, 0.3602, -0.4257, 0.7775], [-0.4390, -0.6274, -0.5100, -0.7316]]) torch.return_types.max( values=tensor([1.7350, 1.0677, 0.8159, 0.7775]), indices=tensor([1, 0, 0, 1])) torch.return_types.max( values=tensor([ 1.0677, 1.7350, -0.4390]), indices=tensor([1, 0, 0])) torch.return_types.max( values=tensor([[1.7350, 1.0677, 0.8159, 0.7775]]), indices=tensor([[1, 0, 0, 1]])) -
torch.argmax(tensor, dim=n): tensor의 요소 중 max 값의 index를 반환한다.이 때, dim=n 요소를 입력하면 dim=n으로 접는다. 예를 들어 dim=0이면 각 열에서 max 값의 index를 추출하여 반환하게 된다.
주의할 점 : tensor의 차원이 2 이상일 때, dim=n 요소를 주지 않으면 가장 마지막 차원의 index가 반환된다.
(코드)
a = torch.randn(3,4) print(a) print(torch.argmax(a)) print(torch.argmax(a, dim=0))(결과)
tensor([[ 1.2001, 2.4138, 0.9824, -0.4469], [ 0.8022, 0.5243, -1.4808, 1.1072], [-0.6110, -0.8182, -0.7366, 0.0525]]) tensor(1) tensor([0, 0, 0, 1])
sum, mean, std 함수
torch.sum(tensor, dim=n, keepdims=True): dim=n으로 쌓은 후 sum 연산을 한다. 예를 들어, 2차원 tensor에서 dim=1 로 설정하면 행 별로 더한다. 결과적으로, dim=n으로 접게 된다.- dim=n 없이 수행하면 모든 요소의 합이 return된다.
- keepdims=True로 설정하면 원본의 차원이 유지된다.
(코드)
a = torch.randn(3,4) print(a) print(torch.sum(a)) print(torch.sum(a, dim=1)) print(torch.sum(a, dim=1, keepdims=True))(결과)
tensor([[-0.4658, 1.1440, 0.1925, 0.8696], [-0.2410, -2.6269, -0.1082, 2.0504], [-2.3266, -0.0603, 1.0653, -0.2424]]) tensor(-0.7494) tensor([ 1.7403, -0.9257, -1.5639]) tensor([[ 1.7403], [-0.9257], [-1.5639]])-
torch.mean(tensor, dim=n): dim=n을 기준으로 평균을 구한다. 결과적으로 dim=n으로 접게 된다.예를 들어, 3*4 모양의 tensor에서 dim=1을 설정하게 되면 각 행의 열 별로 평균을 구한다. 따라서 dim=1(열)로 접게 된다.
(코드)
a = torch.randn(3,4) print(a) print(torch.mean(a)) print(torch.mean(a, dim=1)) print(torch.mean(a, dim=1, keepdims=True))(결과)
tensor([[-0.4658, 1.1440, 0.1925, 0.8696], [-0.2410, -2.6269, -0.1082, 2.0504], [-2.3266, -0.0603, 1.0653, -0.2424]]) tensor(-0.0624) tensor([ 0.4351, -0.2314, -0.3910]) tensor([[ 0.4351], [-0.2314], [-0.3910]]) -
torch.std(tensor): tensor를 구성하는 요소들의 표준편차를 구하는 함수이다.
(코드)
a = torch.randn(3,4) print(a) print(torch.std(a))(결과)
tensor([[-3.4415, 0.9005, 0.3959, 0.7047], [-0.9700, 0.0784, -0.4988, 0.7027], [ 1.7742, -0.8974, 0.0234, -0.9309]]) tensor(1.3290)
1.5 - Tensor 연산
Tensor 변환
선형대수학에서 행렬을 다룰 때 가장 중요한 연산 중 하나가 전치(Transpose) 이다. Pytorch에도 전치를 지원하며, 이를 확장한 개념인 차원의 변환 또한 지원한다.
-
tensor.reshape(shape): 원본 tensor를 원하는 shape으로 변환하는 함수이다. 이 때, 마지막 차원부터 요소를 채우면서 변환한다.이때, shape에 (4,-1)과 같이 대입하면 행의 수는 4, 열의 수는 알아서 변환하게 된다. 예를 들어, tensor의 요소 수가 20개이면 (4,5) shape의 tensor가 생성된다. 따라서 (1,-1) 을 대입하면 2차원 행 벡터, (-1, 1) 을 대입하면 2차원 열 벡터가 생성된다.
(코드)
a = torch.arange(20) print(a) print(a.reshape(4,5) print(a.reshape(4,-1).shape) # (4,5) shape의 tensor 자동 생성(결과)
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]) tensor([[ 0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [10, 11, 12, 13, 14], [15, 16, 17, 18, 19]]) torch.Size([4, 5]) -
tensor.transpose(a,b): dim=a 와 dim=b 가 바뀐다. 이 때, 이 함수는 두 개의 차원만 바꿀 수 있다.예를 들어,
tensor.transpose(0,2)는 dim=0과 dim=2를 바꾼다.
(코드)
a = torch.randn(2,3,4) print(a) print(a.transpose(0,2).shape) print(a.transpose(0,2))(결과 : dim=0과 dim=2가 바뀐 것을 확인할 수 있음)
tensor([[[-1.1991, 0.3728, 0.2659, -0.2742], [-0.9017, -0.1994, 0.7568, 1.8734], [-0.6094, -0.1875, -0.9871, 0.0358]], [[-1.6260, 0.5890, 0.5562, -1.1465], [-0.4583, 0.5209, 0.2618, -1.1267], [ 1.0217, 2.1956, 0.4245, 0.4243]]]) torch.Size([4, 3, 2]) tensor([[[-1.1991, -1.6260], [-0.9017, -0.4583], [-0.6094, 1.0217]], [[ 0.3728, 0.5890], [-0.1994, 0.5209], [-0.1875, 2.1956]], [[ 0.2659, 0.5562], [ 0.7568, 0.2618], [-0.9871, 0.4245]], [[-0.2742, -1.1465], [ 1.8734, -1.1267], [ 0.0358, 0.4243]]]) -
tensor.permute(0,2,1): 위의 transpose 함수는 두 차원만 바꿀 수 있었다. 그러나 permute 함수는 두 개 이상의 차원을 바꿀 수 있도록 한다.예로, (0,2,1) 의 숫자는 각각 원본 tensor의 차원의 index를 의미하며 원본의 (0,1,2) 번째 차원을 (0,2,1) 순서대로 바꾸라는 뜻이다. 즉, 이 예시에는 2 번째 차원과 1 번째 차원을 바꾸게 된다.
(코드)
a = torch.randn(2,3,4) print(a) print(a.permute(0,2,1).shape) print(a.permute(0,2,1))(결과)
tensor([[[ 0.1425, -0.4132, 0.9183, -1.1303], [-1.3723, -0.5931, -0.9790, 0.0322], [-0.3236, 0.7203, -0.9767, -0.1053]], [[-1.1121, -2.2002, -1.3496, 0.1428], [-0.1689, -0.9300, -2.0065, -0.0144], [ 0.4352, 1.2080, 1.7478, 2.1088]]]) torch.Size([2, 4, 3]) tensor([[[ 0.1425, -1.3723, -0.3236], [-0.4132, -0.5931, 0.7203], [ 0.9183, -0.9790, -0.9767], [-1.1303, 0.0322, -0.1053]], [[-1.1121, -0.1689, 0.4352], [-2.2002, -0.9300, 1.2080], [-1.3496, -2.0065, 1.7478], [ 0.1428, -0.0144, 2.1088]]])
Tensor 차원 축소/확장
상황에 따라 필요 없는 차원을 줄이거나 늘려야 할 수 있다. 이럴 때를 위해 아래의 함수를 사용한다.
-
tensor.squeeze(): 유효하지 않은 차원을 줄이는 함수이다. 즉, size가 1인 차원을 없애 유효한 shape을 만들어준다.예를 들어, (1,1,2,3) shape의 tensor를 squeeze한다면 그 결과로 (2,3) shape의 tensor를 얻을 수 있다.
(코드)
a = torch.randn(1,1,2,3) print(a.shape) print(a.squeeze().shape)(결과)
torch.Size([1, 1, 2, 3]) torch.Size([2, 3]) -
tensor.unsqueeze(dim=n): 원하는 위치에 차원을 늘리는 함수이다.예를 들어, (2,3) shape의 tensor의 dim=1에 unsqueeze한다면 그 결과로 (2,1,3) shape의 tensor를 얻을 수 있다.
(코드)
a = torch.randn(2,3) print(a.shape) print(a.unsqueeze(dim=1).shape)(결과)
torch.Size([2, 3]) torch.Size([2, 1, 3])
Tensor 병합
딥러닝 학습 데이터를 이용할 때, 두 dataset을 합치거나 feature와 label을 합치는 등의 여러 상황에서 tensor를 병합해야 한다. 이럴 때 사용할 수 있는 함수가 아래 함수들이다.
-
torch.vstack([a,b]): dim=0 에 a와 b를 쌓는다.예를 들어, 두 tensor a와 b가 각각 23 shape일 때 dim=0에 쌓으면 43 shape의 tensor를 얻는다. 즉, 2차원인 경우 수직 방향(vertical)으로 쌓기 때문에 vstack이다.
그러나 2차원 이상에서는 수직으로 쌓는다는 개념보다는 dim=0에 쌓는다는 개념이 적용하기 쉽다.
(코드)
a = torch.randn(2,3) b = torch.randn(2,3) print(a) print(b) print(torch.vstack([a,b]))(결과)
tensor([[-0.0438, -1.0970, -1.9101], [-0.1366, -2.3687, -1.7195]]) tensor([[ 1.5016, -1.1989, -0.6355], [-0.3517, 0.5741, 0.2791]]) tensor([[-0.0438, -1.0970, -1.9101], [-0.1366, -2.3687, -1.7195], [ 1.5016, -1.1989, -0.6355], [-0.3517, 0.5741, 0.2791]]) -
torch.hstack([a,b]): dim=1 에 a와 b를 쌓는다.예를 들어, 두 tensor a와 b가 각각 23 shape일 때 dim=1에 쌓으면 26 shape의 tensor를 얻는다. 즉, 2차원인 경우 수평 방향(horizontal)으로 쌓기 때문에 hstack이다.
그러나 2차원 이상에서는 수평으로 쌓는다는 개념보다는 dim=1에 쌓는다는 개념이 적용하기 쉽다.
(코드)
a = torch.randn(2,3) b = torch.randn(2,3) print(a) print(b) print(torch.hstack([a,b]))(결과)
tensor([[-0.8676, -0.7816, 0.2995], [-2.2452, -1.0152, -1.6314]]) tensor([[ 0.1893, 0.2046, 0.7424], [-0.8871, -0.5741, 0.2163]]) tensor([[-0.8676, -0.7816, 0.2995, 0.1893, 0.2046, 0.7424], [-2.2452, -1.0152, -1.6314, -0.8871, -0.5741, 0.2163]]) -
torch.cat([a,b], dim=n): dim=n 에 a와 b를 쌓는다.위
vstack과hstack에서 설명했듯 tensor의 차원이 3 이상일 때는 세로, 가로 개념이 불분명해지기 때문에cat을 사용하는 것이 도움이 된다.
(코드)
a = torch.randn(2,3,4) b = torch.randn(2,3,4) print(torch.cat([a,b], dim=0).shape) print(torch.cat([a,b], dim=1).shape) print(torch.cat([a,b], dim=2).shape)(결과)
torch.Size([4, 3, 4]) torch.Size([2, 6, 4]) torch.Size([2, 3, 8])
행렬 곱
Pytorch에서 tensor끼리의 곱은 크게 두 가지로 나눌 수 있다. 바로 Element-wise 곱과 Matrix 곱이다.
-
Element-wise 곱 :
*연산자와mul()함수를 통해 수행한다. element-wise 곱이란 동일 위치에 있는 원소끼리의 곱을 뜻한다.
(코드)
a = torch.tensor([ [1,2], [3,4] ]) b = torch.tensor([ [5,6], [7,8] ]) print(a*b) print(a.mul(b))(결과)
tensor([[ 5, 12], [21, 32]]) tensor([[ 5, 12], [21, 32]]) -
Matrix 곱 :
@연산자와matmul()함수를 통해 수행한다.
(코드)
a = torch.tensor([ [1,2], [3,4] ]) b = torch.tensor([ [5,6], [7,8] ]) print(a@b) print(a.matmul(b))(결과)
tensor([[19, 22], [43, 50]]) tensor([[19, 22], [43, 50]])
matrix 곱을 할 때 이런 의문이 생길 수 있다. 3차원 이상의 tensor 끼리의 곱은 어떻게 될까?
이에 대한 답은 간단하다. 바로 마지막 두 차원의 matrix 곱으로 결정된다.
예를 들어, a가 (12,8,3,4) shape의 tensor, b가 (12,8,4,7) shape의 tensor라면 두 tensor의 matrix 곱은 (12,8,3,7) shape의 tensor가 결과로 나온다.
(코드)
a = torch.randn(12,8,3,4) b = torch.randn(12,8,4,7) print((a@b).shape)(결과)
torch.Size([12, 8, 3, 7])